Our Approach
We've built InReach as a modular sign language translation system that separates computer vision tasks from language translation tasks. This architectural decision ensures robustness, maintainability, and the ability to improve each component independently.
System Architecture Overview
InReach is built as a distributed system with all AI processing happening client-side for privacy and offline capability. Below is our high-level system context:
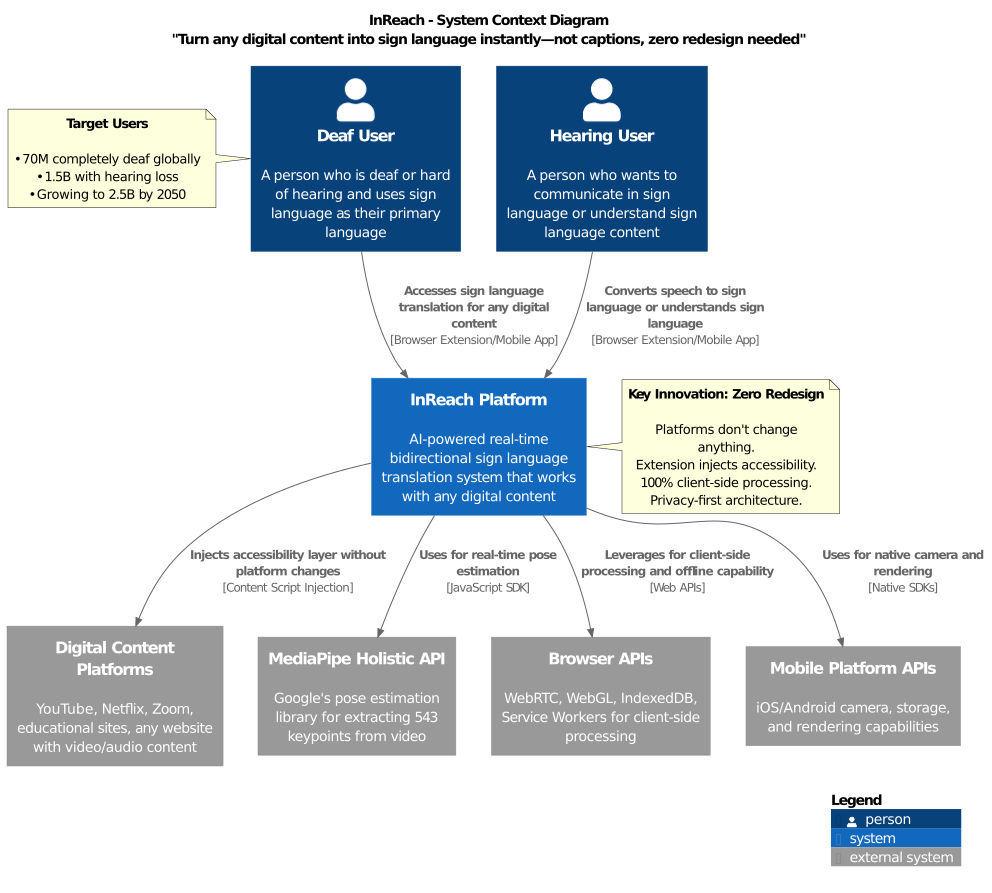
InReach integrates with any digital platform without requiring changes, serving deaf users, hearing users, and institutions through browser extensions, mobile apps, and optional APIs.
Spoken-to-Signed Language Translation
Below is the technical pipeline powering our spoken-to-signed translation. Each node represents a distinct module in our architecture.
Container Architecture
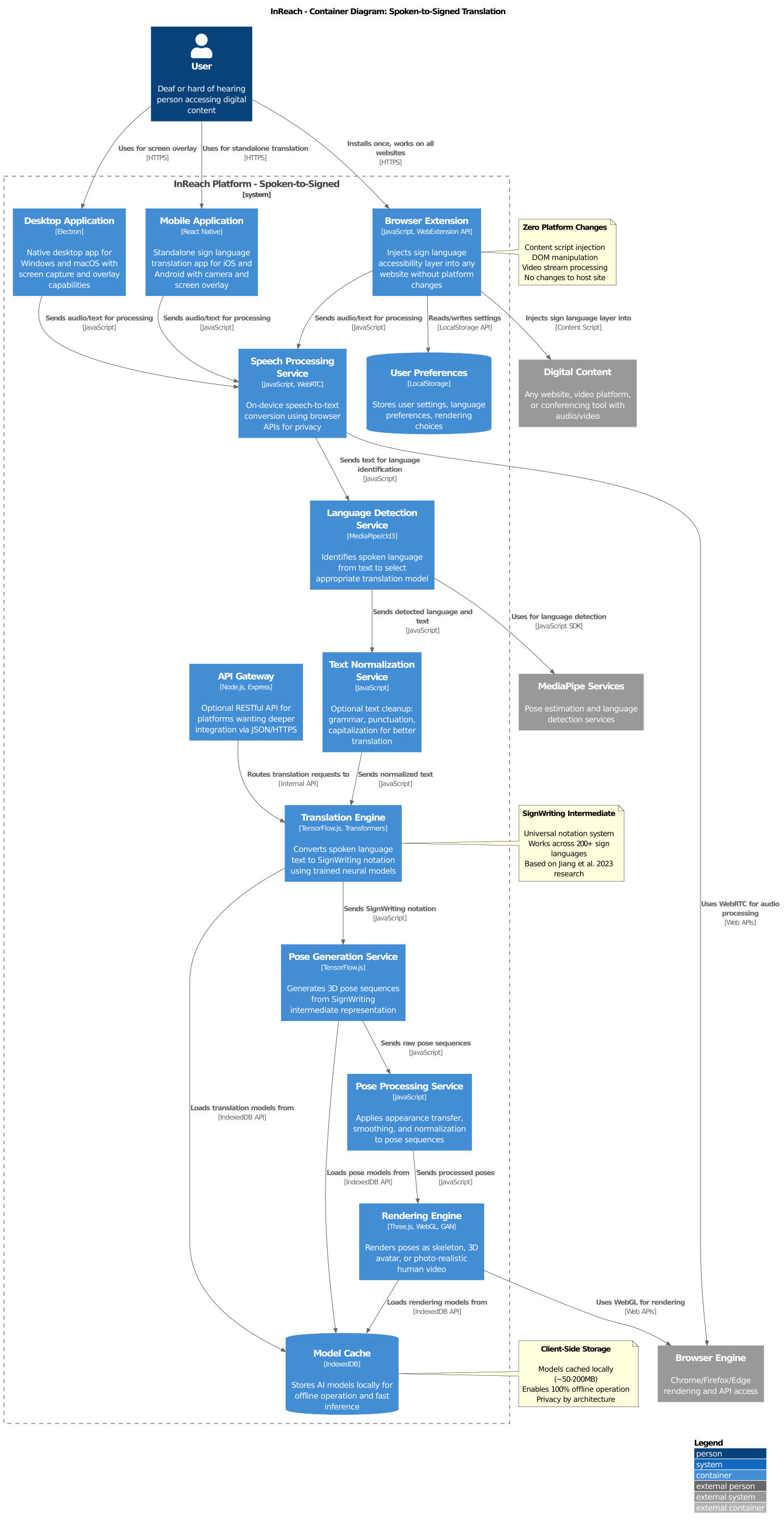
The spoken-to-signed pipeline processes audio or text input through language detection, normalization, and translation to SignWriting, then generates pose sequences and renders them as sign language video—all on the user's device.
Pipeline Overview
Pipeline Status Legend:
- Green edges: Production-ready, high-quality modules
- Orange edges: Functional but need optimization
- Red edges: In development, contributions welcome
InReach implements two parallel translation approaches, each with distinct trade-offs:
- Dictionary-Based Translation (Baseline)
- SignWriting-Based Machine Translation (Primary)
Dictionary-Based Translation
Our baseline approach uses dictionary lookup for rapid deployment but sacrifices linguistic accuracy and natural fluency. This method serves as a fallback and benchmark for measuring improvements in our primary approach.
Translation Pipeline
- Text-to-Gloss Conversion: Input text undergoes lemmatization, word reordering, and article removal to approximate sign language structure
- Gloss-to-Pose Mapping: Glosses are matched to pre-recorded skeletal poses from our sign language dictionary
- Pose-to-Video Rendering: Pose sequences are interpolated and rendered into video output
Data Requirements
Requires a comprehensive dictionary of isolated signs (letters, words, phrases) in video format. Current coverage: ~10,000 signs across major sign languages.
Known Limitations
- Incomplete representation: Glosses cannot capture the full grammatical complexity of sign languages
- Missing linguistic features: Facial expressions, spatial grammar, and non-manual markers are poorly represented
- Unnatural output: Interpolation between dictionary signs lacks the fluency of native signing
- Limited expressiveness: Cannot handle classifiers, role-shifting, or contextual modifications
Use case: Fallback for unsupported language pairs, baseline for quality comparison, rapid prototyping.
SignWriting-Based Machine Translation
Our primary approach treats sign language translation as a true machine translation problem, comparable in quality and fluency to systems like Google Translate. This enables bidirectional translation and respects the linguistic complexity of sign languages.
Translation Pipeline
- Text-to-SignWriting Translation: Neural machine translation models convert spoken language into SignWriting notation (Formal SignWriting format)
- SignWriting-to-Pose Generation: SignWriting sequences are animated into fluent 3D pose sequences using trained models
- Pose-to-Video Rendering: Pose sequences are rendered into photo-realistic or avatar-based video output
Data Strategy
We synthesize large-scale training data by combining:
- ~100k isolated signs: Manually transcribed with SignWriting annotations
- Segmented continuous signing: Natural signing with phrase boundaries
- Large video corpora: Automatically transcribed using the above as seed data
This bootstrapping approach generates millions of training examples for both translation stages without requiring full manual annotation.
Quality Targets
- Linguistic accuracy: Preserves sign language grammar, spatial relationships, and non-manual features
- Natural fluency: Generates signing that native signers recognize as natural
- Expressiveness: Handles lexical signs, classifiers, facial expressions, and role-shifting
- Bidirectionality: Enables both spoken-to-signed and signed-to-spoken translation
Target performance: Comparable to human interpreters on benchmark datasets (BLEU >40, native signer preference >70%).
Why SignWriting Works Better
SignWriting serves as an intermediate representation that bridges the modality gap between spoken language (linear text) and sign language (spatial, multi-channel). Unlike glosses:
- Captures non-manual features: Facial expressions, head movements, body posture
- Preserves spatial grammar: Location, orientation, and movement in signing space
- Supports linguistic analysis: Enables proper machine translation techniques
- Universal notation: Works across 200+ sign languages with minor adaptations
Example 1: Robustness to Variations
Minor spelling variations in the input (even incorrect ones) produce the same correct SignWriting output, while dictionary translation fails—demonstrating that our machine translation understands meaning, not just string matching.
Example 2: Emotional Context
Changing punctuation (exclamation vs. question) produces different facial expressions in SignWriting output, while dictionary translation is identical. Non-manual features (facial expressions) carry grammatical meaning in sign languages—our system learns this from data.
Signed-to-Spoken Language Translation
Our signed-to-spoken pipeline enables deaf individuals to communicate with hearing individuals by translating sign language videos into spoken language text or audio.
Container Architecture
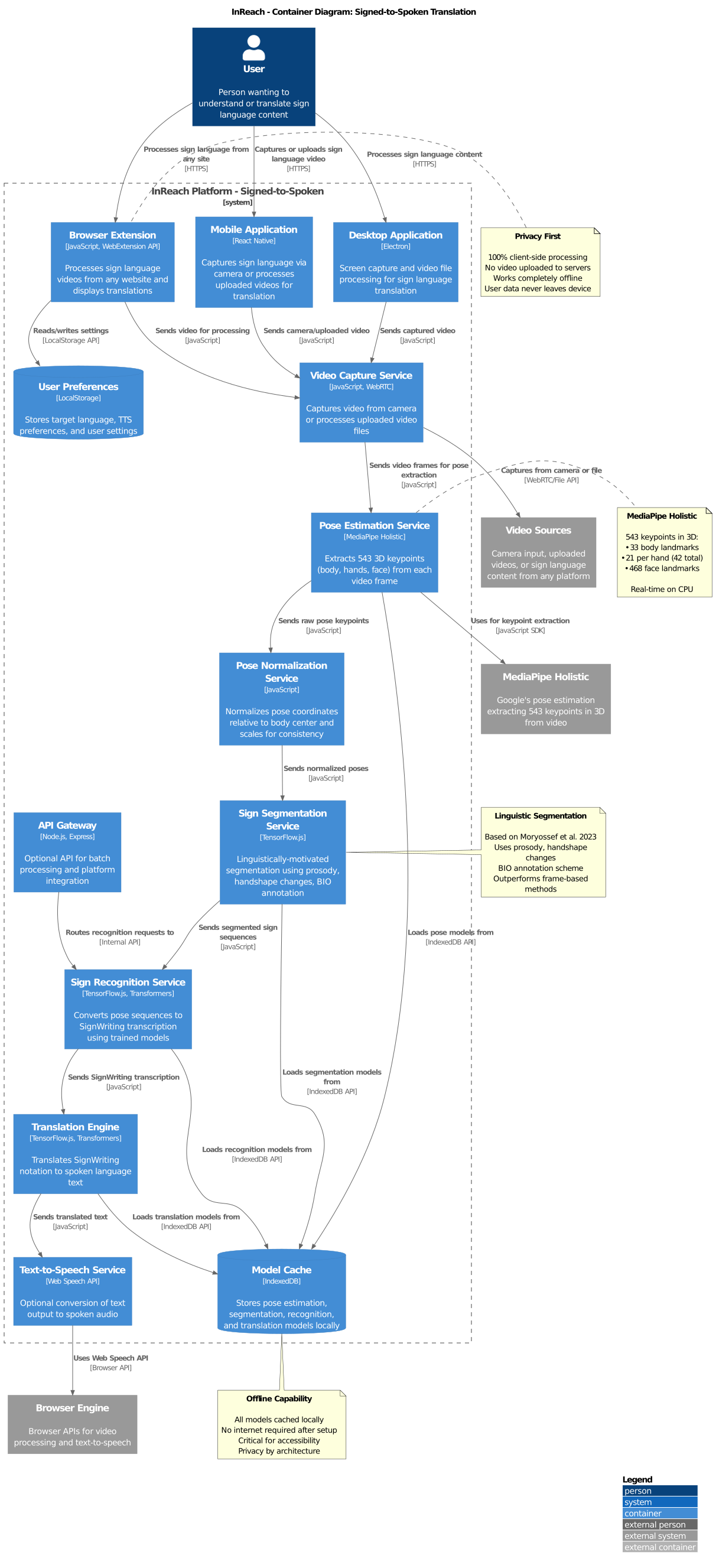
The signed-to-spoken pipeline captures video, extracts pose keypoints using MediaPipe Holistic, segments signs using linguistic cues, recognizes them as SignWriting, and translates to spoken language—entirely on the user's device for privacy.
Pipeline Overview
Pipeline Status:
- Pose Estimation: Production-ready using MediaPipe Holistic (543 keypoints)
- Segmentation: Functional, based on linguistic cues
- SignWriting Transcription: In development, improving accuracy
- Translation: Leverages same models as spoken-to-signed (bidirectional)
Key Challenge: Sign language recognition is inherently harder than production due to:
- Signer variation (regional accents, personal styles)
- Video quality and lighting conditions
- Occlusion and motion blur
- Co-articulation between signs
Current Focus: Improving segmentation accuracy and expanding training data with diverse signers.
Deployment Architecture
InReach's "zero redesign needed" promise is enabled by our client-side deployment model:
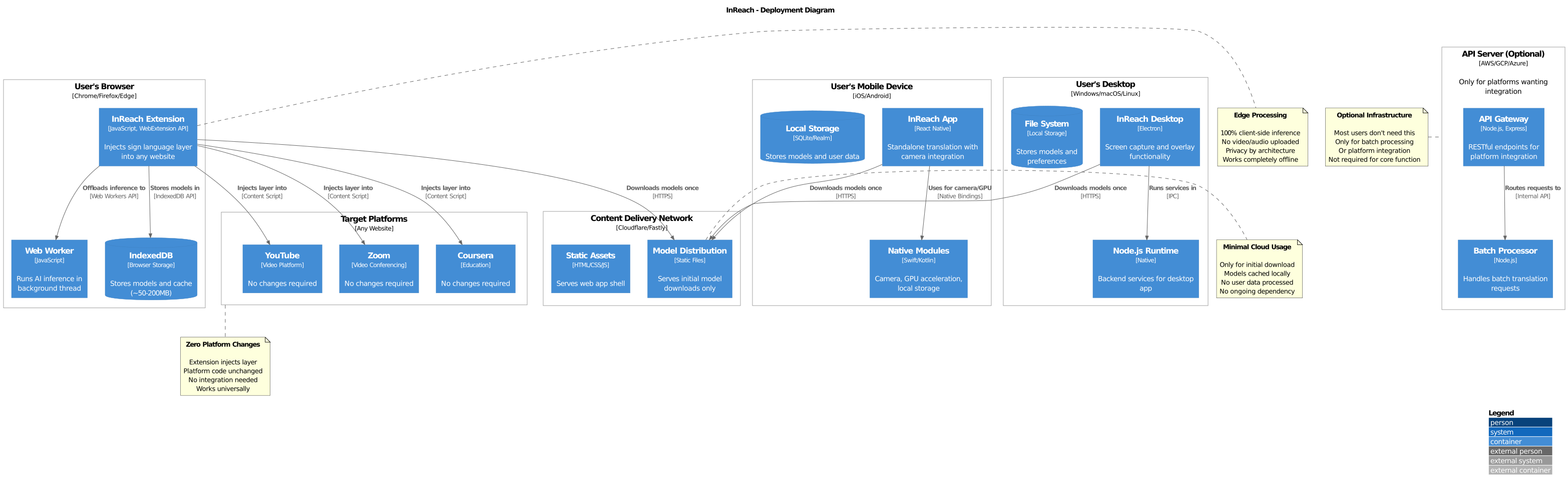
All processing happens on user devices (browser, mobile, desktop) with models cached locally. Optional CDN serves initial downloads only. Target platforms require zero changes—extensions inject accessibility layers seamlessly.
Integration Methods
- Browser Extension: Injects sign language layer into any website
- Mobile Apps: Standalone translation with camera integration
- Desktop Apps: Screen capture and overlay functionality
- API/SDK: Optional integration for platforms wanting deeper embedding
Client-Side Processing
All translation happens on the user's device:
- Privacy: No video or audio uploaded to servers
- Offline capability: Works without internet connection
- Zero platform changes: Host platforms remain unchanged
- Scalability: No server costs, unlimited users
Technology Stack
- Frontend: Progressive Web Apps, React Native, Electron
- AI/ML: TensorFlow.js, MediaPipe Holistic, Transformer models
- Rendering: Three.js (3D Avatar), WebGL (Skeleton), GANs (Photo-realistic)
- Storage: IndexedDB (models ~50-200MB), LocalStorage (preferences)